Elasticsearch的相关知识及基本使用
Elasticsearch学习笔记
一、基本概念
1、Index(索引)
动词,相当于mysql中的insert
名词,相当于mysql中的Database
2、Type(类型)
在Index中,可以定义一个或多个类型
类似于mysql中的Table;每一种类型的数据放在一起
3、Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的,Document就像是mysql的某个Table里面的内容
4、倒排索引机制
分词:将整句分拆为单词
保存的记录:
1-小米手机
2-小米
3-高粱小米
4-小米手机公司
5-特价小米
| 词 | 记录 |
|---|---|
| 小米 | 1,2,3,4,5 |
| 手机 | 1,4 |
| 公司 | 4 |
| 高粱 | 3 |
| 特价 | 5 |
检索:
1、小米手机
2、小米
计算出相关性得分
例如:检索小米手机:1号数据两个词命中两个词,4号数据三个词命中两个词
二、安装Elasticsearch
1、下载镜像安装
1 | docker pull elasticsearch:7.6.2 |
2、创建目录
1 | #创建目录 |
3、启动
1 | #更改目录权限 |
三、初步检索
1、cat
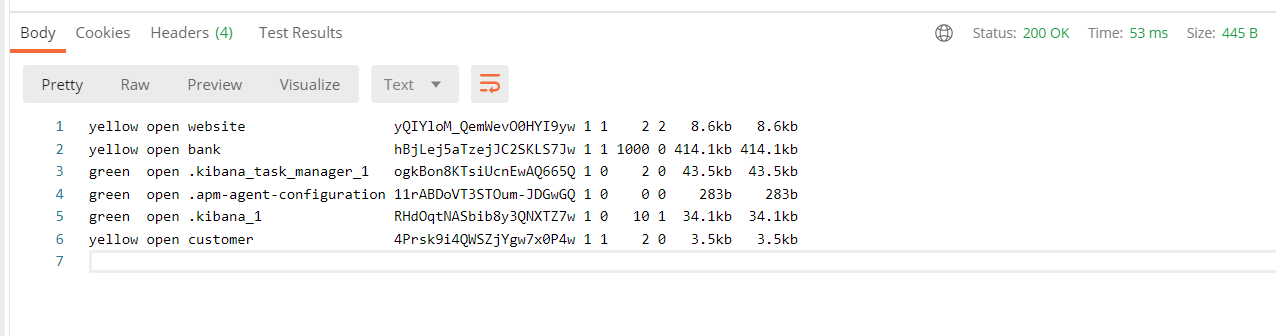
GET/_cat/nodes:查看所有节点

GET/_cat/health:查看es健康状况

GET/_cat/master:查看主节点

GET/_cat/indices:查看所有索引
2、索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
1 | #PUT customer/external/1; 在customer索引下的external类型下保存1号数据为 |
示例:

PUT和POST都可以
POST新增。如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
PUT可以新增也可以修改。PUT必须指定id;由于PUT需要指定id,我们一般用来做修改操作,不指定id会报错。
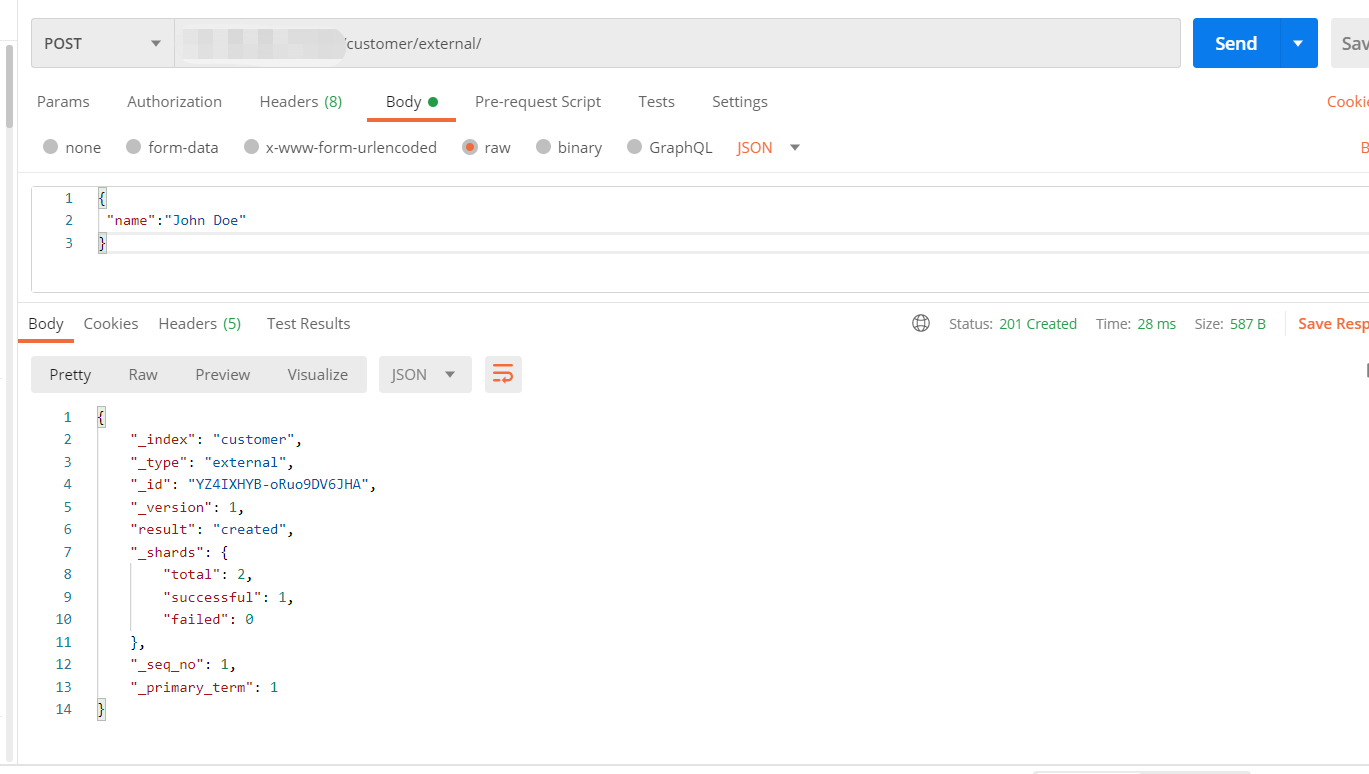
带有下划线开头的,称为元数据,反映了当前的基本信息。
“_index”: “customer” 表明该数据在哪个数据库下;
“_type”: “external” 表明该数据在哪个类型下;
“_id”: “1” 表明被保存数据的id;
“_version”: 1, 被保存数据的版本
“result”: “created” 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。
3、查询文档
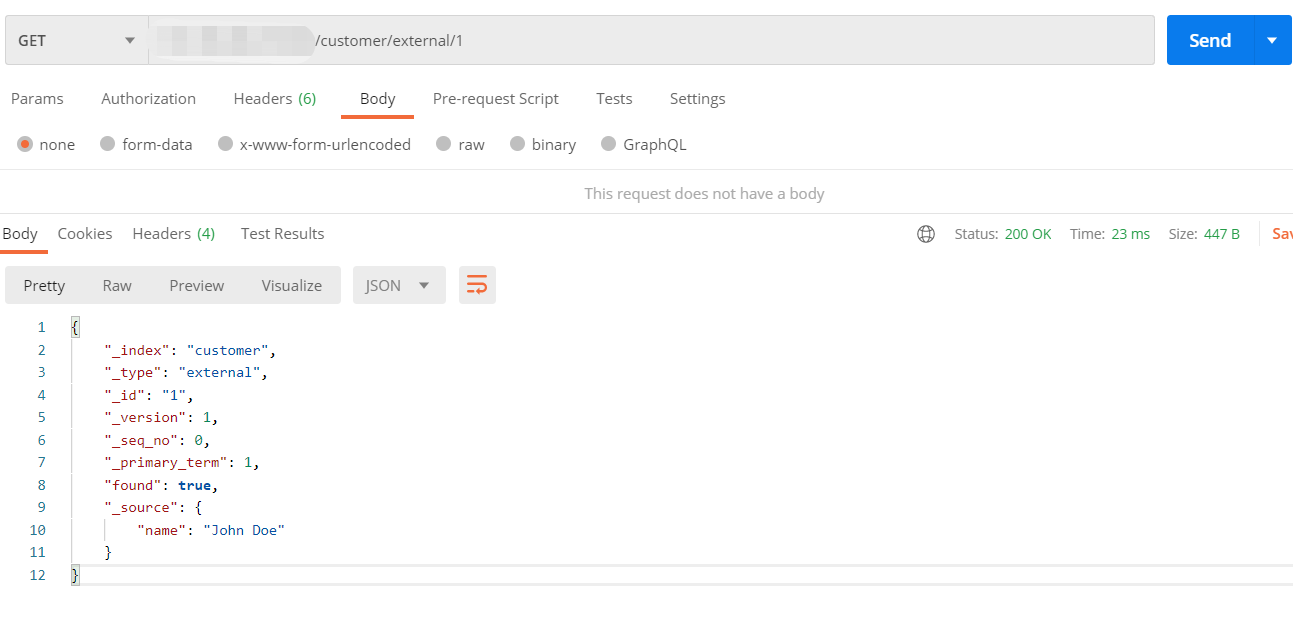
1 | { |
4、更新文档
1 | #方式一 |
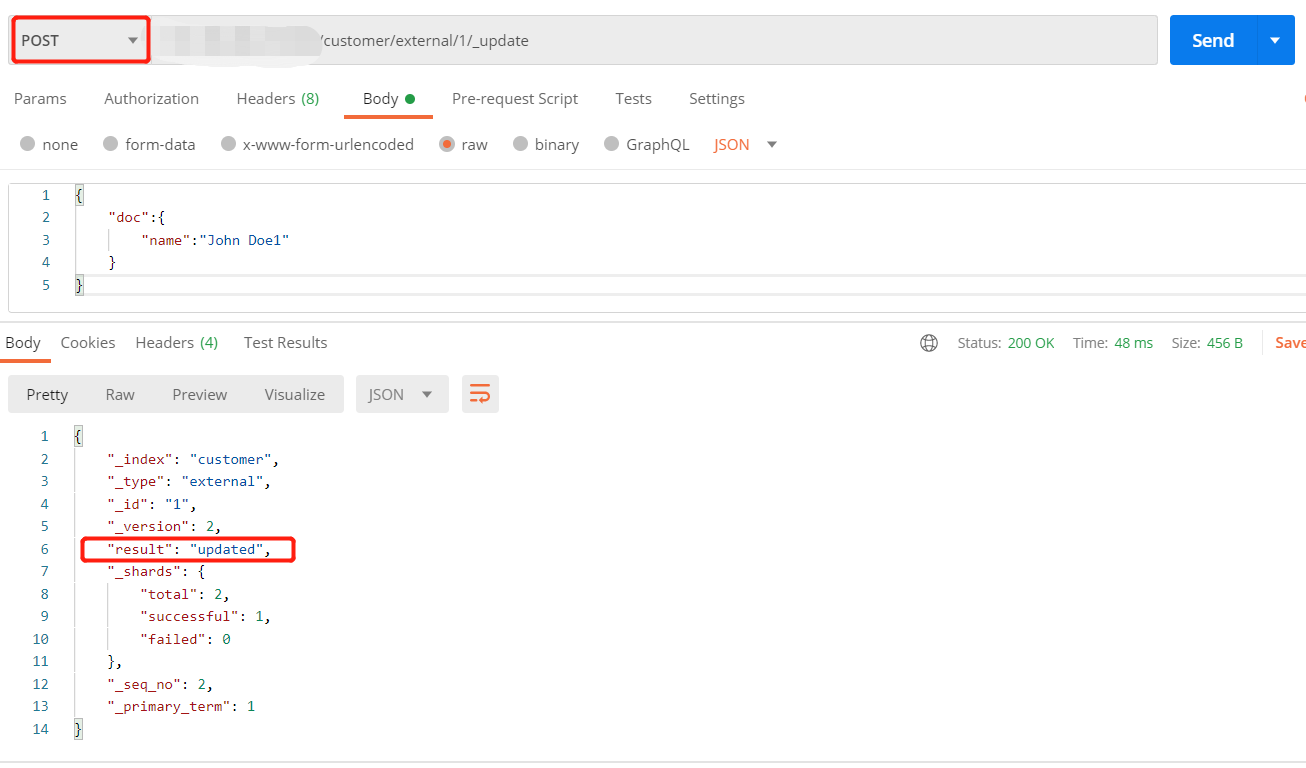
方式一更新时会对比元数据,如果多次执行同一更新,当数据不发生变化,则不执行任何操作,版本号和序列号(version和_seq_no)不会发生变化
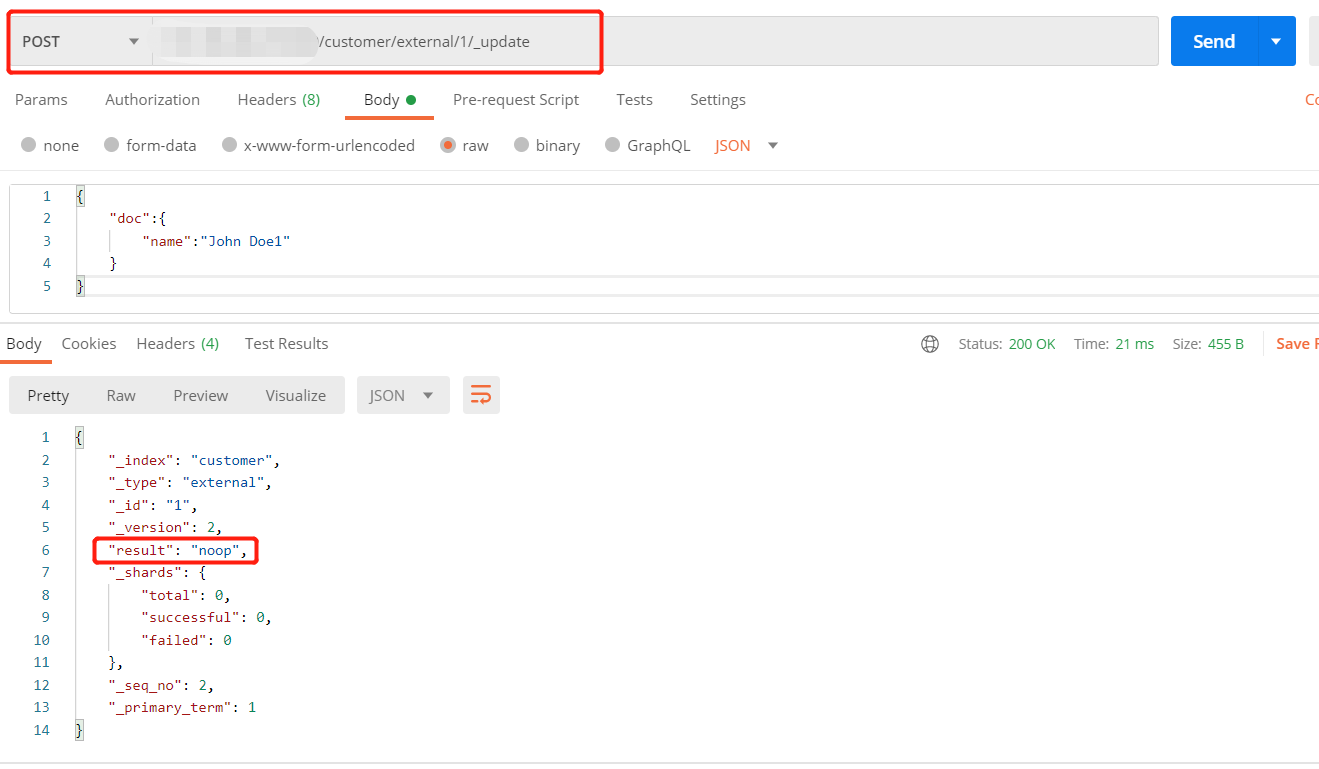
1 | #方式二 |
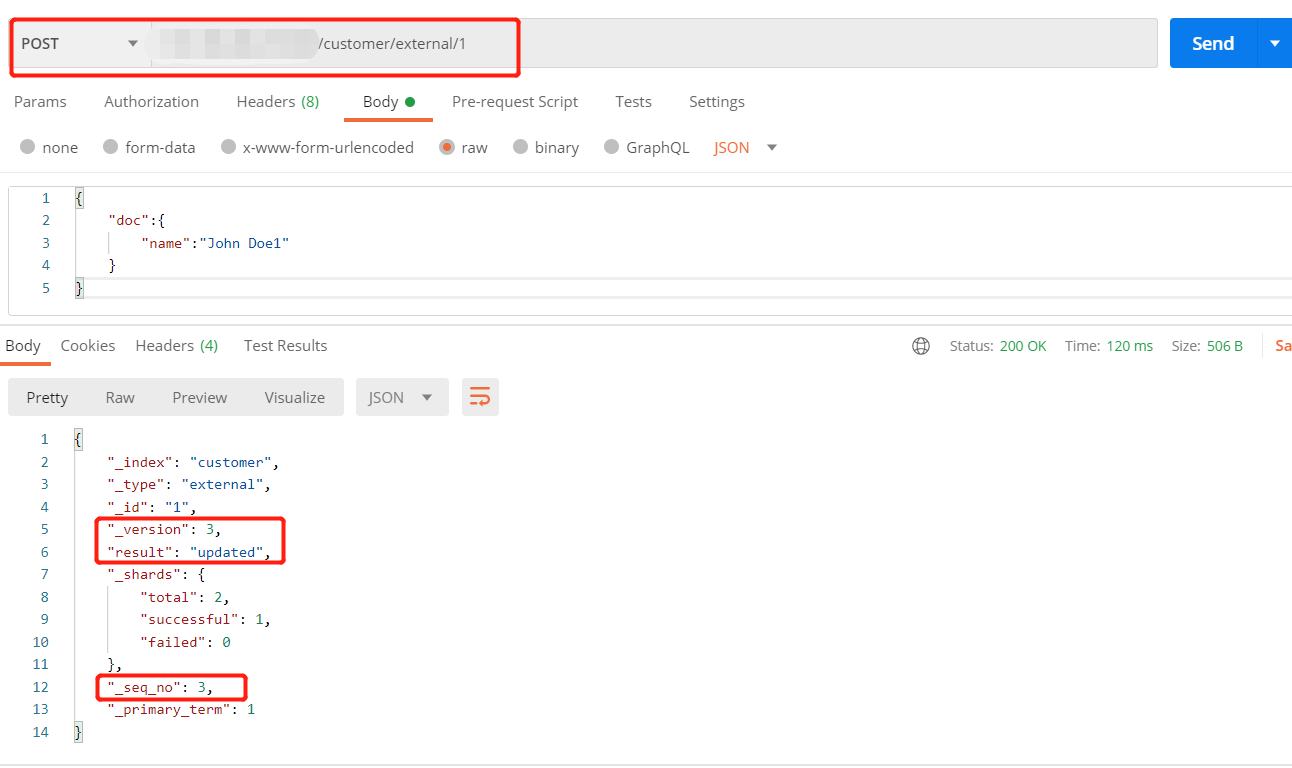
方式二和方式三执行多次更新时,重复执行同一更新操作,数据可以都更新成功,不会和原来的数据进行对比,版本号和序列号(version和_seq_no)会发生变化
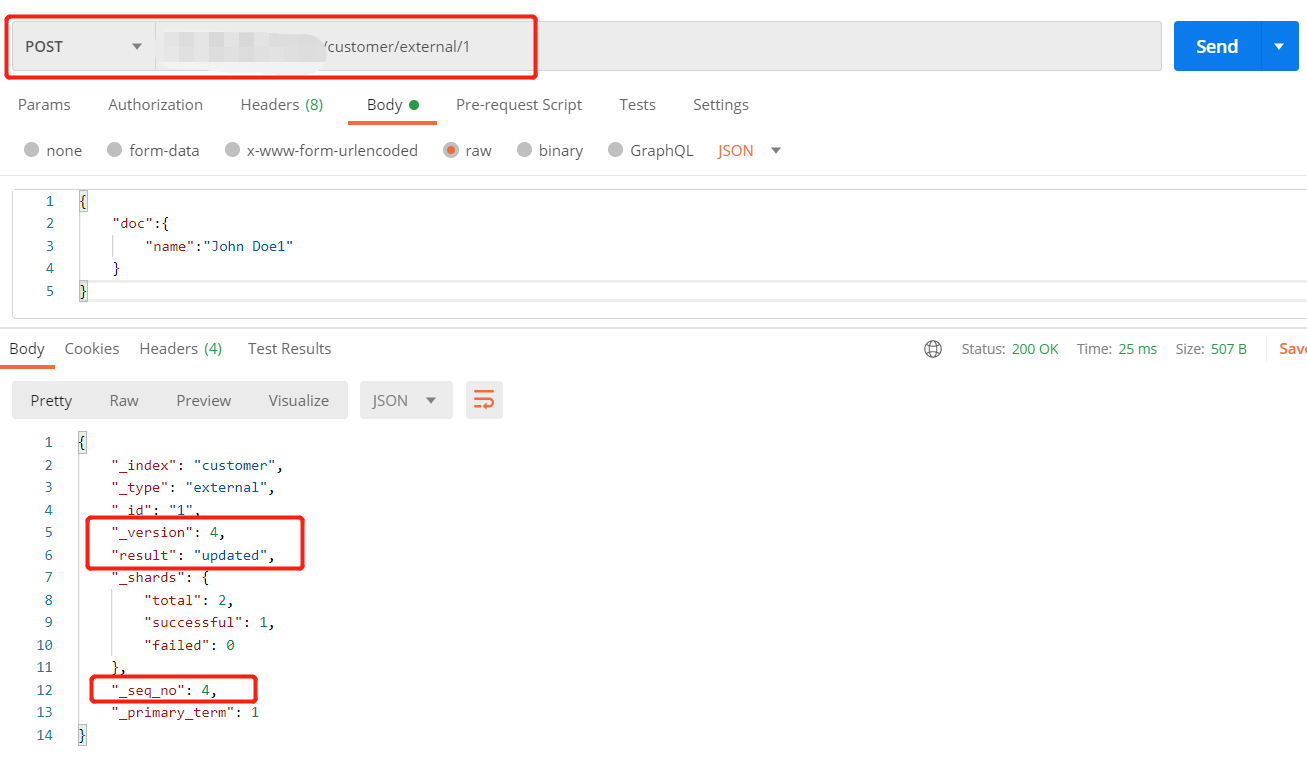
1 | #方式三 |
1 | ##更新同时增加属性时三种方式都可以更新成功,方式一同样会对比数据 |
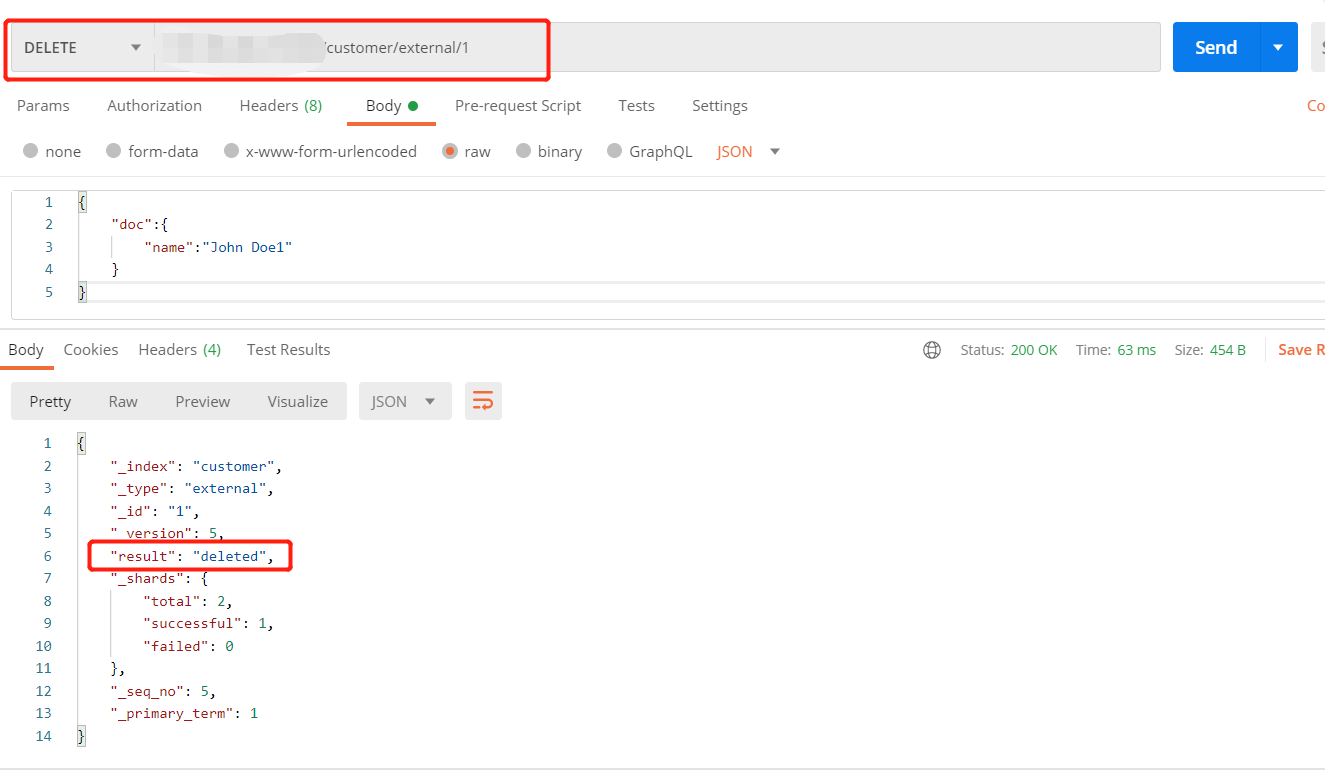
5、删除文档
1 | ##删除某一条数据 |
1 | ##删除整个索引 |
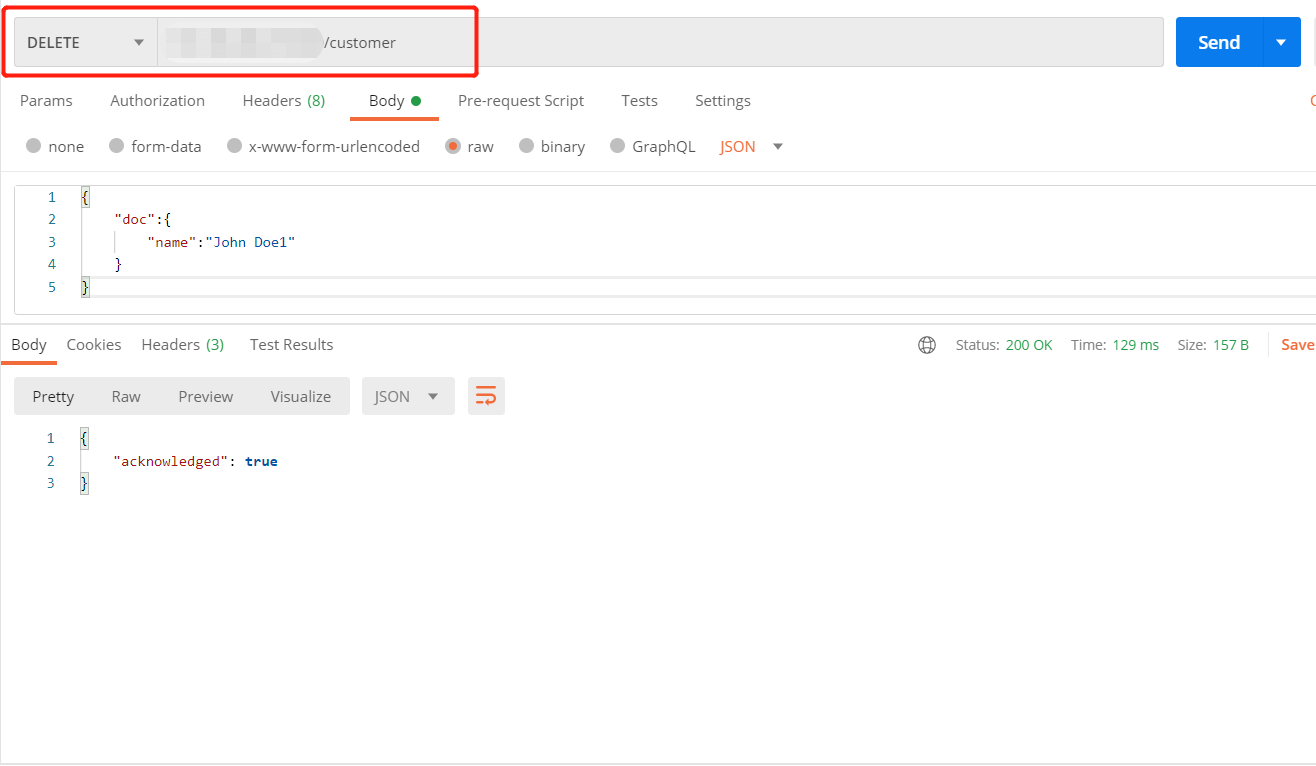
Elasticsearch没有删除类型(Type)
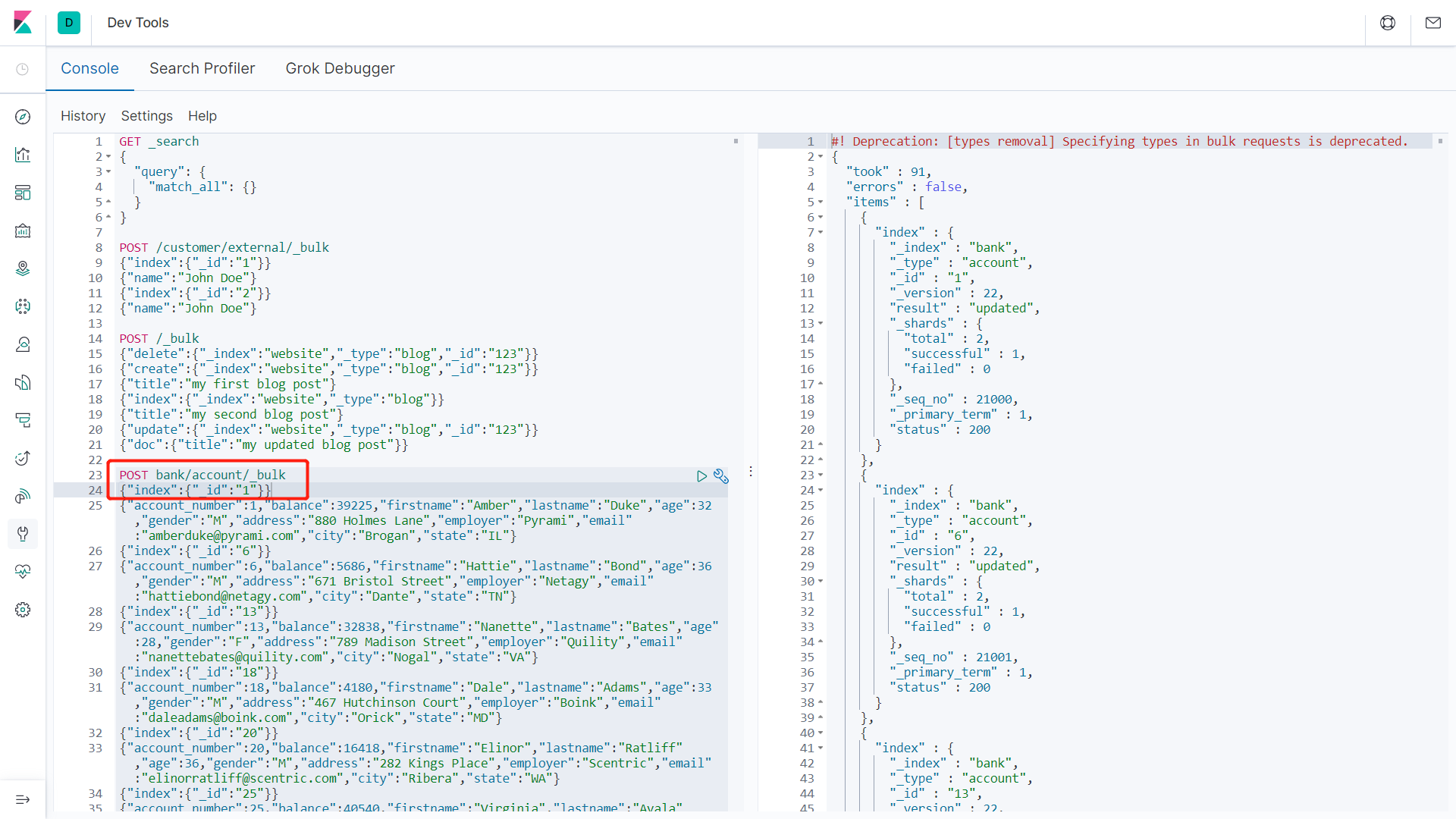
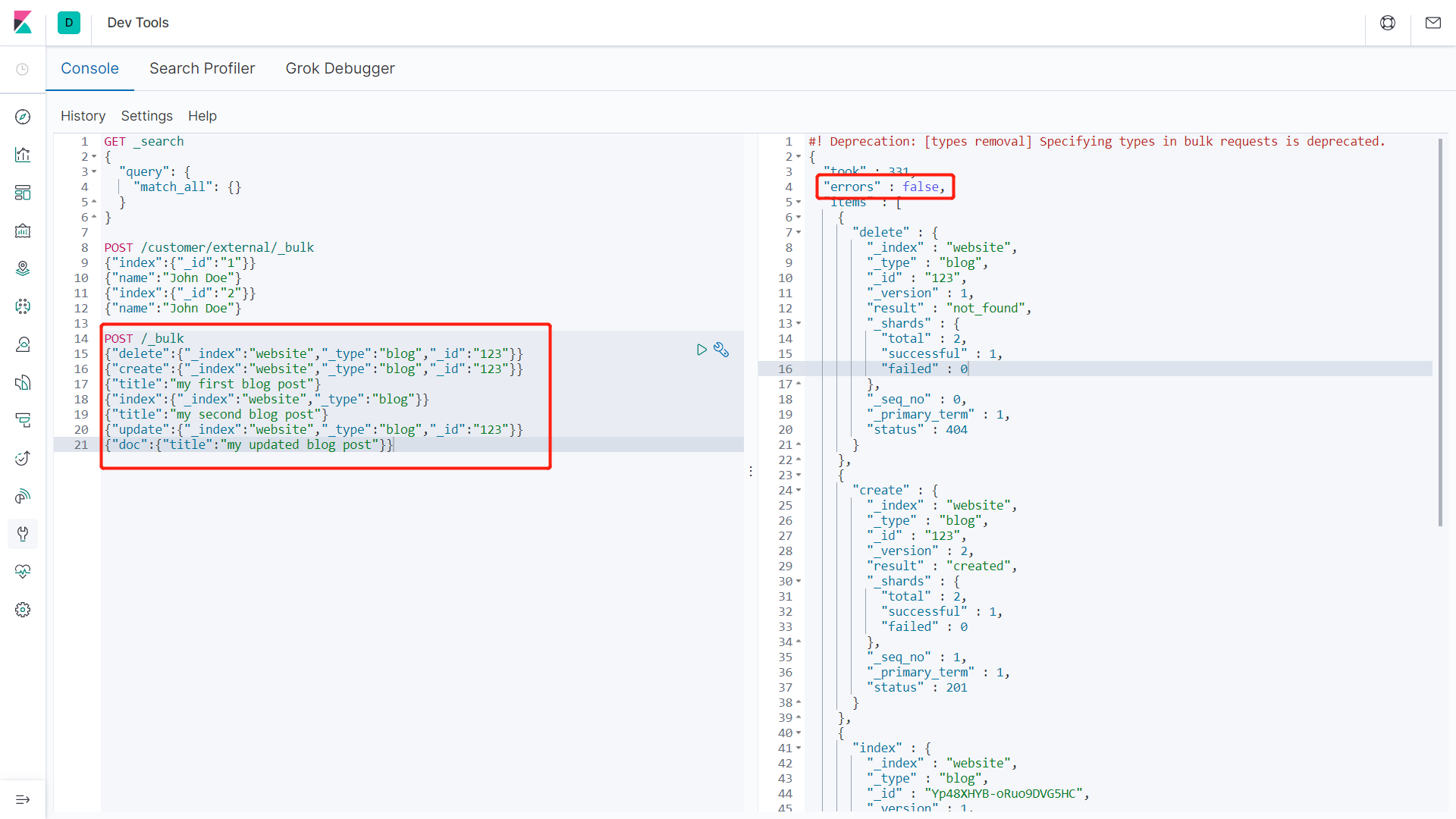
6、bulk批量API
语法格式:
1 | {action:{metadata}}\n |
示例1:
1 | POST customer/external/_bulk |
执行结果:
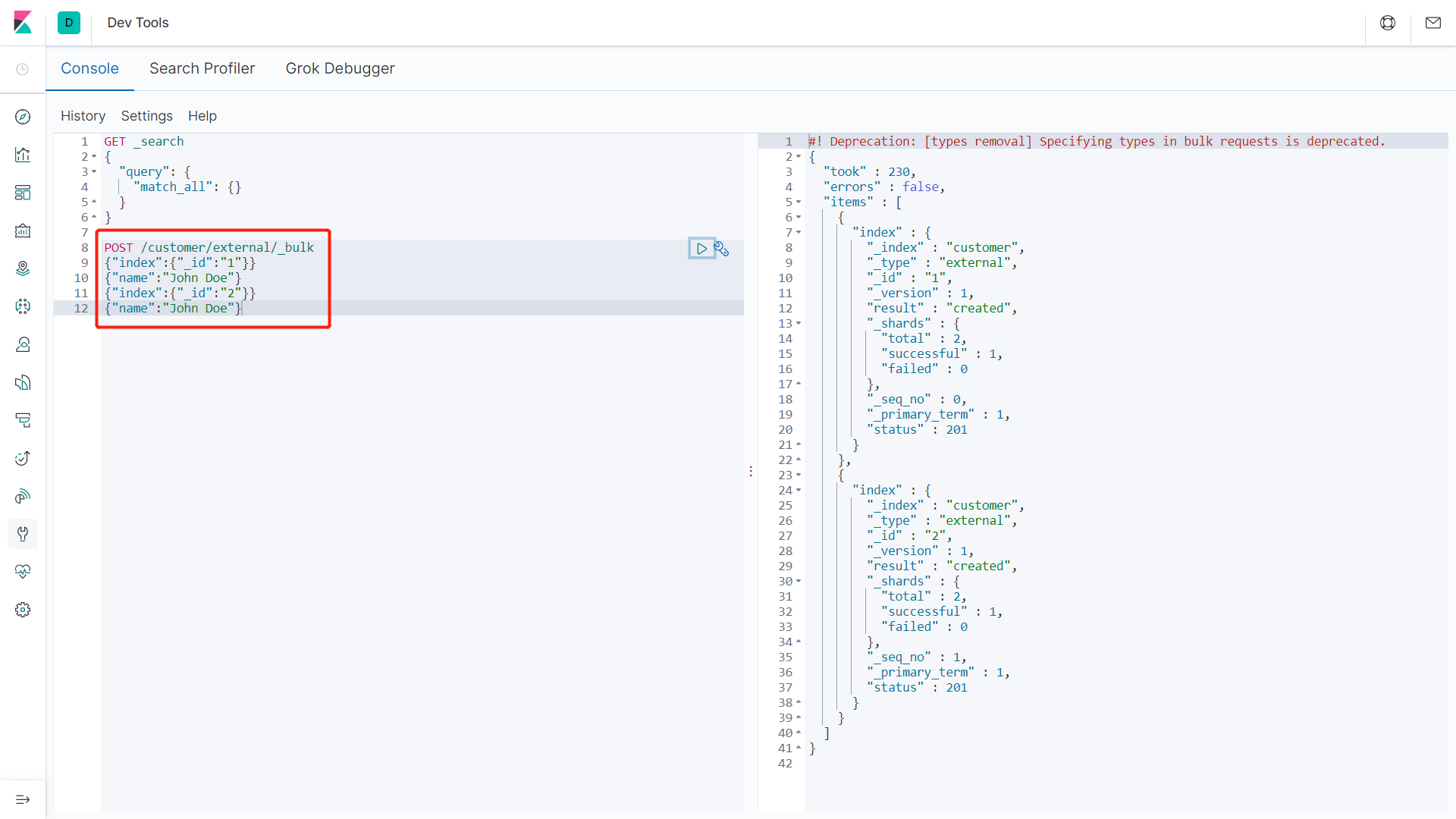
批量操作时,当某一条执行发生失败时,其他的数据仍然能够接着执行,彼此之间是独立操作的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以可以检查是否一个指定的动作是否失败了。
示例2:
1 | #没有指定任何索引的任何类型,说明是对整个ES的批量操作 |
执行结果:
添加样本测试数据
官方提供的批量样本测试数据:https://github.com/elastic/elasticsearch/edit/master/docs/src/test/resources/accounts.json
1 | POST bank/account/_bulk |
执行结果: